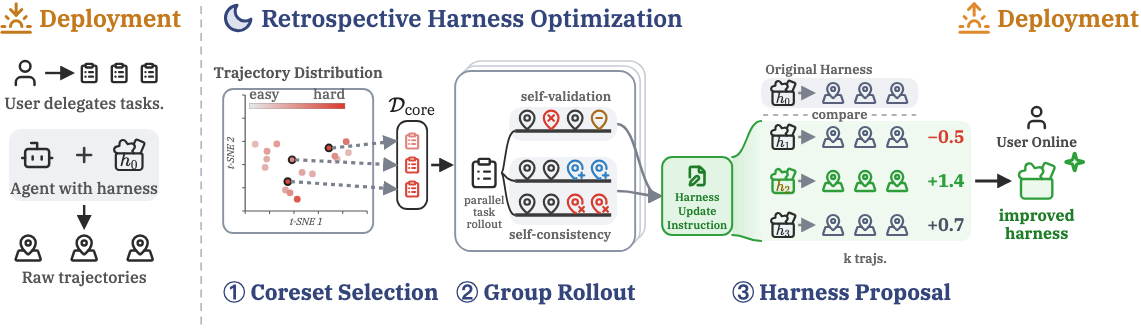
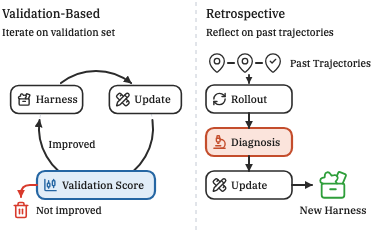
No validation set, no feedback loop
Validation-feedback methods repeatedly score harness edits against labeled data. RHO instead reflects on past trajectories in a single retrospective pass — replacing the external grader with the agent's own self-validation, self-consistency, and self-preference.



